Project information
- Category: Deep Learning
- Project date: Jan 2024 - May 2024
- Project URL: GitHub Link
Visual Question Answering on Medical Dataset
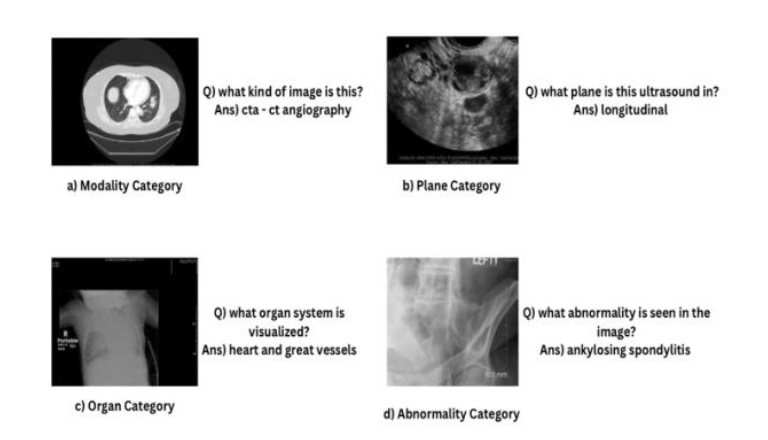
This project focuses on applying Visual Question Answering (VQA) technology to the medical domain, specifically for analyzing radiology scans.VQA combines computer vision and natural language processing techniques to interpret and answer questions based on visual information.
The goal is to develop an advanced VQA system tailored for medical datasets, leveraging the powerful BLIP (Bootstrapping Language-Image Pre-training) architecture from Salesforce. BLIP is a state-of-the-art multimodal model for Image Scene Understanding.
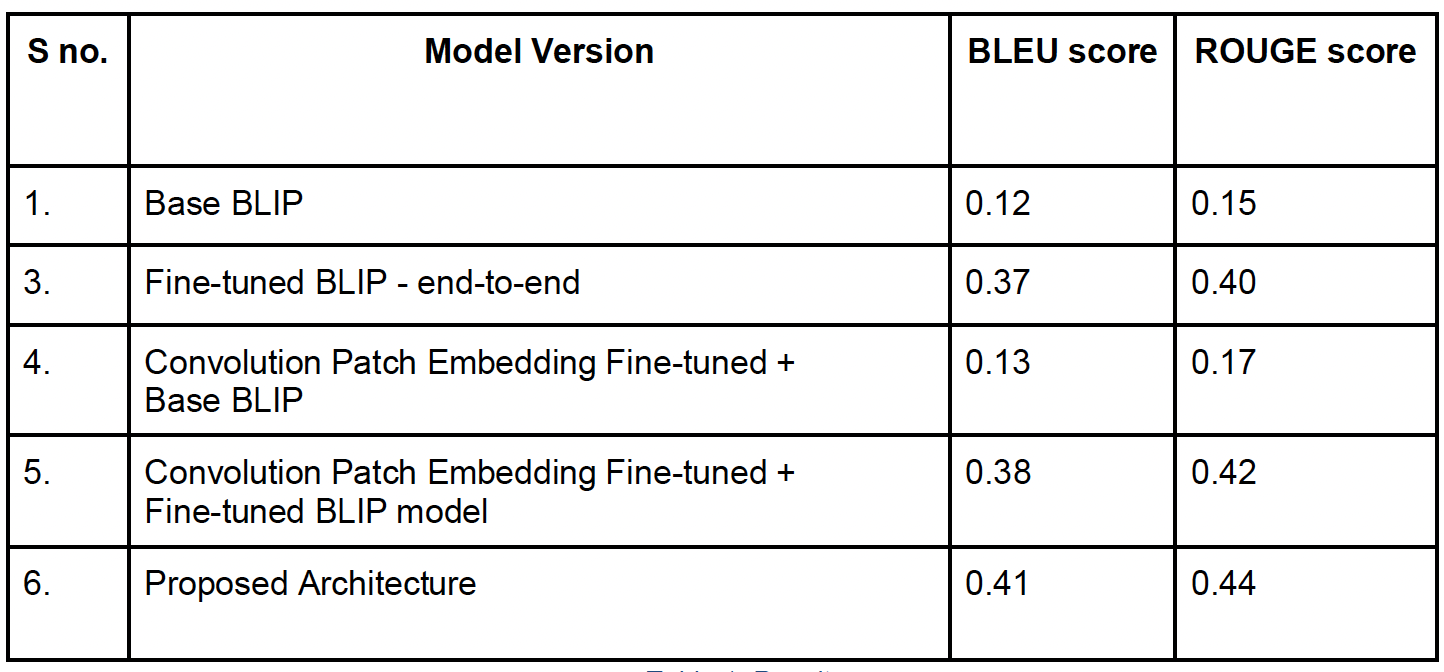
We employed deep learning and transfer learning techniques, including fine-tuning, optimization, and architectural tweaks, to adapt the BLIP model to the unique challenges of medical imaging data. Our goal was to improve the model's performance metrics, such as BLEU and ROUGE scores, for accurate and reliable medical VQA.
- Fine tuned BLIP architecture on medial dataset.
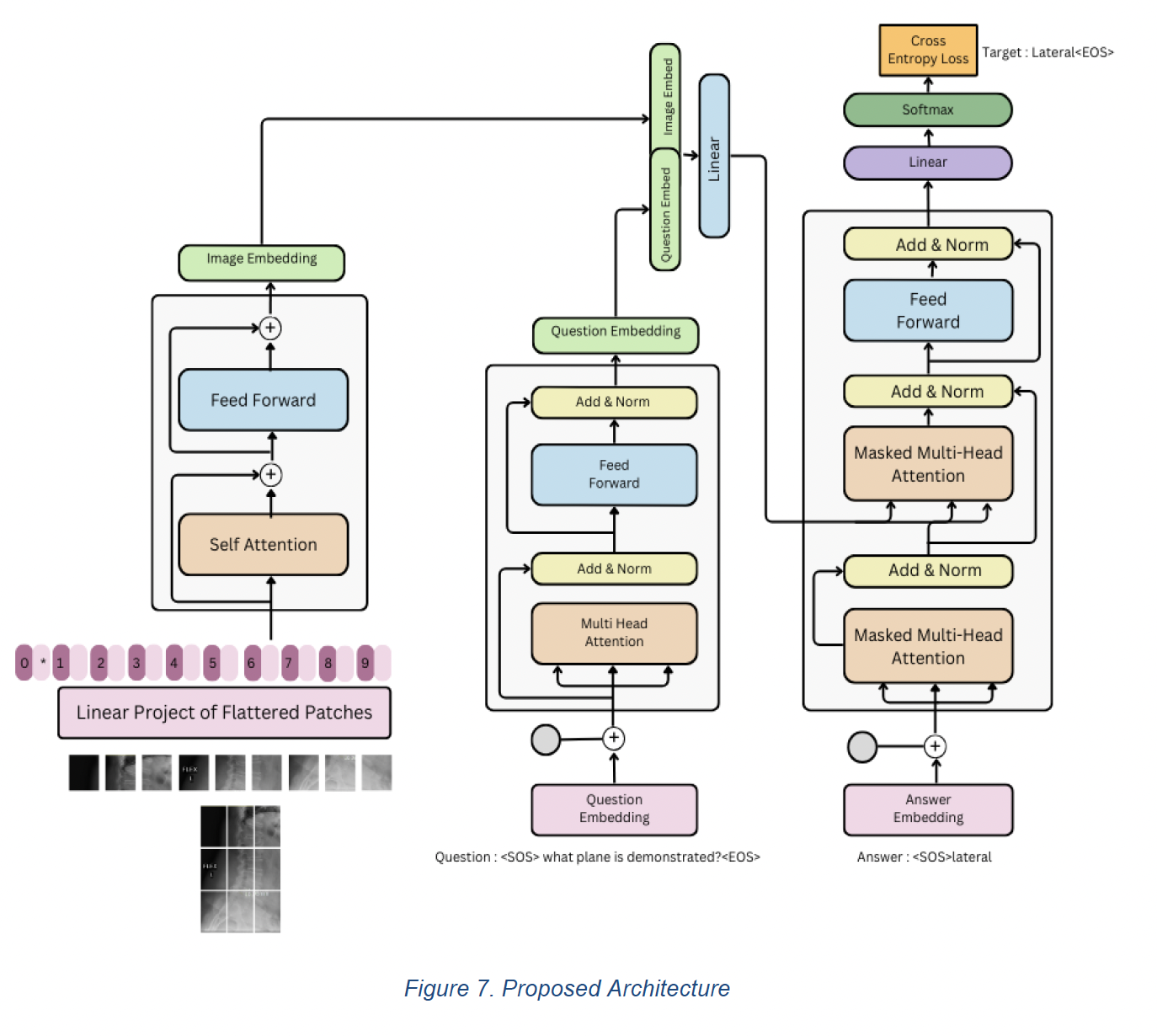
- Since the BLIP model has two text encoders and one image encoder, the image encoder is specifically fine-tuned, and its weights are plugged in.
- Inspired by the success of the BLIP architecture, we proposes a novel multimodal fusion approach specifically tailored for medical visual question answering.